
Ch.1 Language Processing and Python
NLTK is a program in python that makes natural language processing easy to learn. Natural language is the language used in everyday communication by humans (vs. artificial language like programming languages or mathematical notations).
Searching Text
Searching text teaches us how to search words an get styles of texts from words around the text (context)
Functions used…
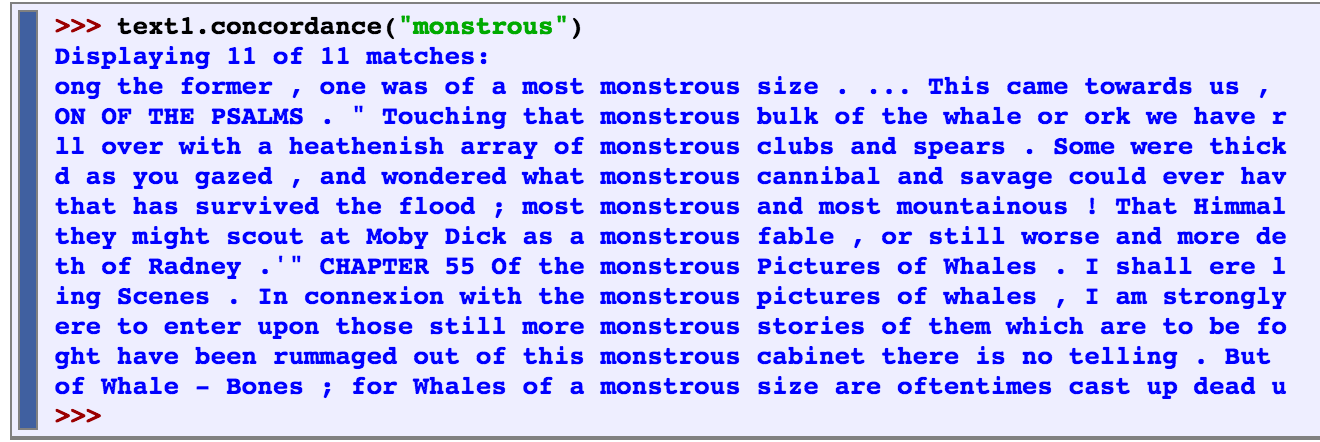
.concordance – used to print word with context when it appears in the text
.similar – used to print words in a similar range of context
.common_contexts – used to examine contexts shared by two or more words
.dispersion_plot – allows us to visually see patterns of word usage in a text
.generate – outputs random text with words used in the given text. (this function is helpful in that it reuses common words and phrases within the text which gives a sense of style and content)
EXAMPLES

![]()
![]()
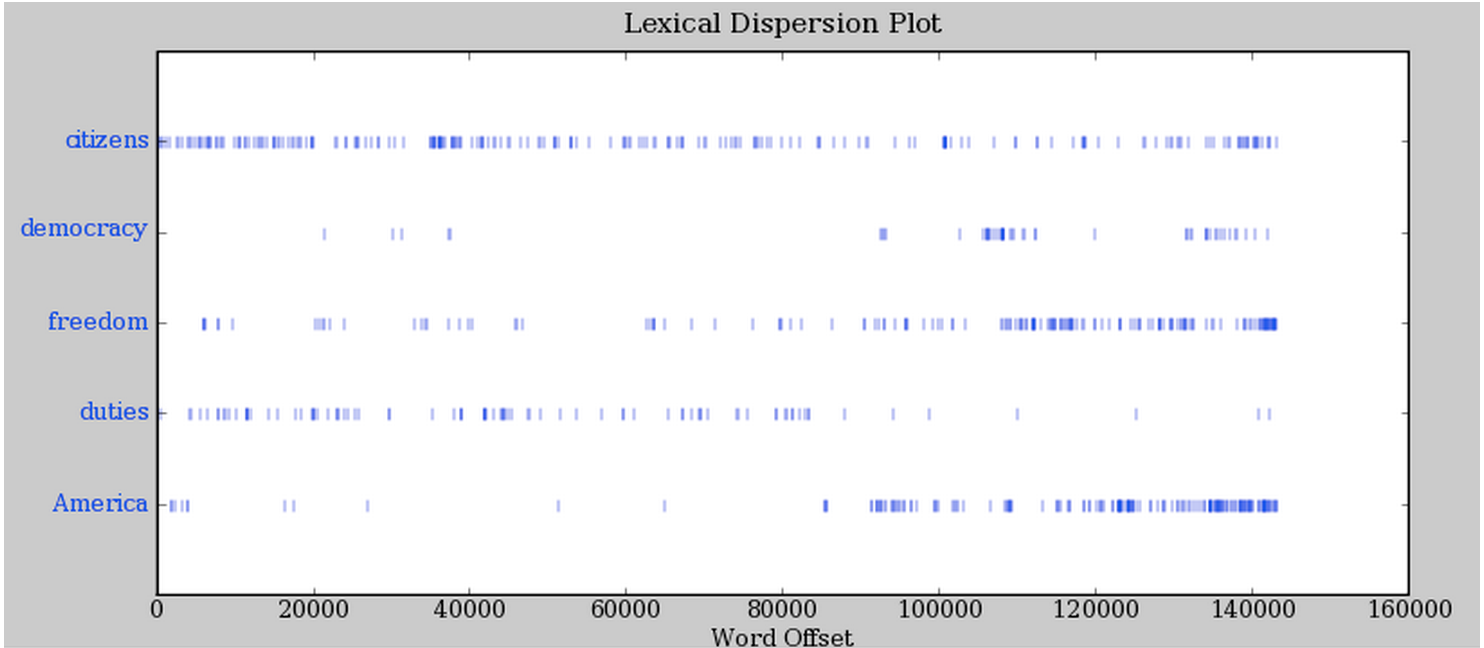
Counting Vocabulary
Counting vocabulary is helpful in searching text because each text differs in length. Different lengths constitute different writing styles (ie. the length difference between a messaging chat versus a novel)
token – a word or punctuation symbol
set – tokens with no duplicates
sorted – sorts tokens in order of punctuation, capitalized words, then lowercase words
Functions used…
.count – counts occurrences of a word (useful for figuring out genre)
we can count how many words are in a body of text, and count how many times a specific word occurs.

Lists
Lists kind of act as arrays in that you can put multiple numbers or phrases in brackets and assign them to a variable as a whole.
![]()
With lists, we can add or concatenate another list to the end of one.![]()
We can also append words onto lists.

Indexing Lists
indexing lists are good for locating specific texts
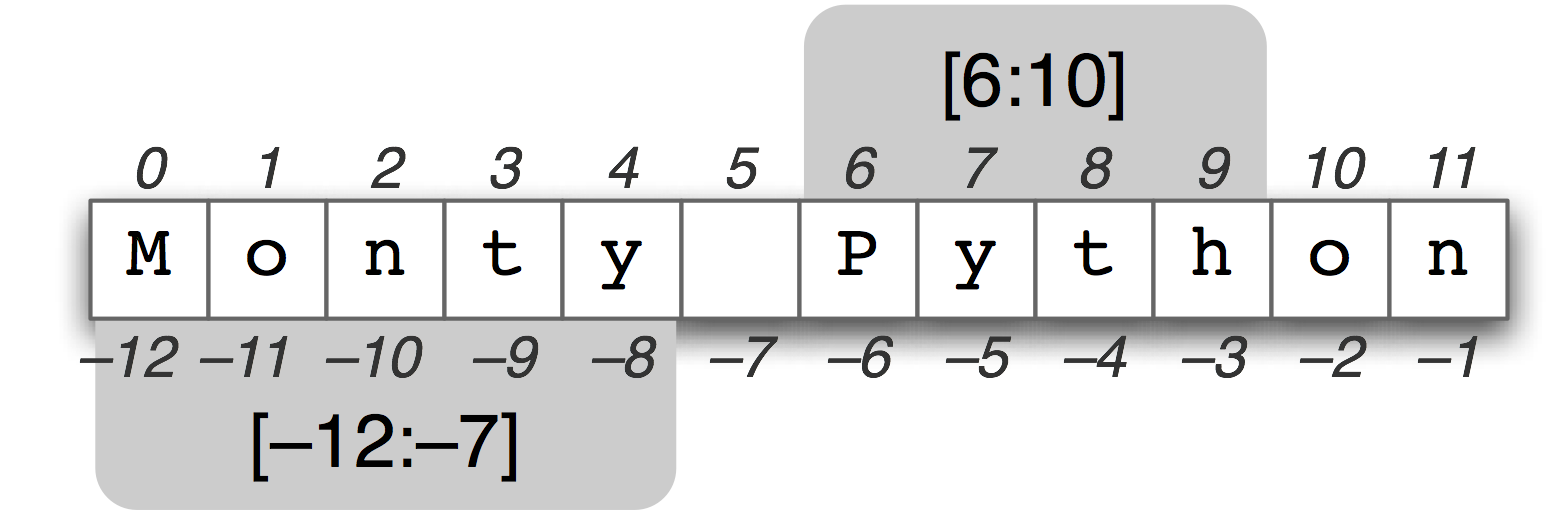
slicing – useful for gathering manageable pieces of text from larger text
*remember that indexing starts at zero, not one

strings – can be multiplied and added them together whereas lists can only add and append

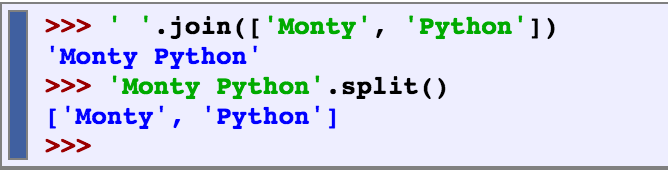
Join and Split
We can also use the .join and .split functions to join the words of a list into a single string, and split a string into a list.
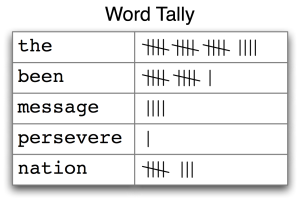
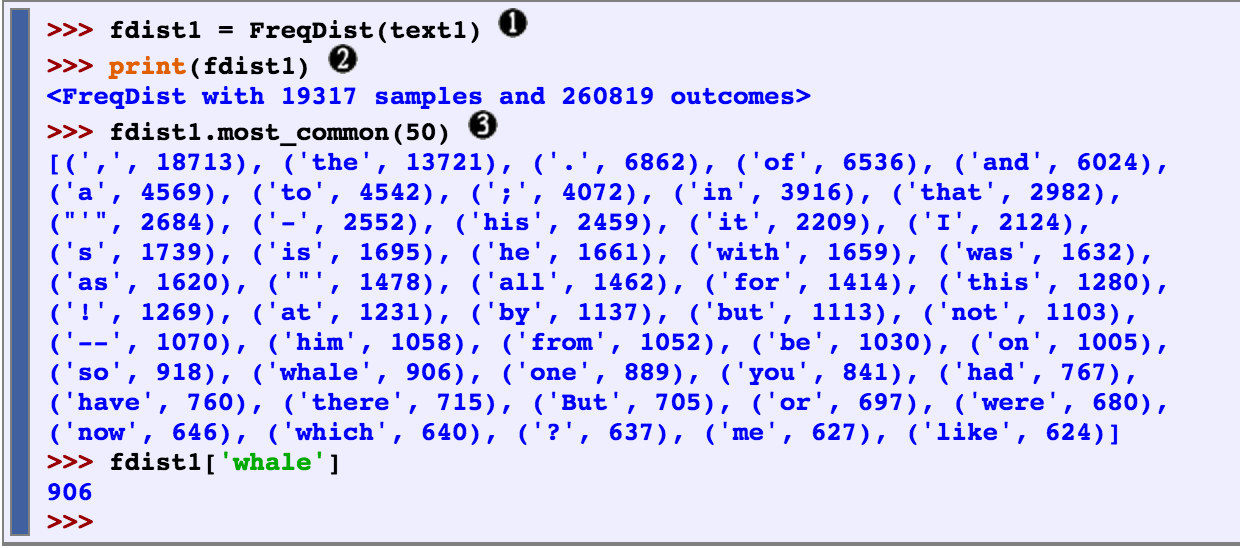
Frequency Distribution
Frequency distribution is useful when trying to quickly identify words in a text that are most informative of a topic and genre. We can use the FreqDist() function to calculate word lengths in a text, and how many words of that length occur (this is useful in differentiating between authors, genres, and languages.
The .most_common function prints out the most common tokens used in a text as seen in the second example. We can also look up a word to see how many times it is used in a text as seen in the last example.
Collocations and Bigrams
collocation – a sequence of words that occur unusually often (ie. United States, high school, pink lemonade)
bigram – a list of word pairs
The collocation function is useful to narrow down a specific genre. It is hard to replace word pairs, and usually word pairs that occur frequently in a text give an idea of what the text is about.
![]()

Helpful Program Tools
.lower – converts all words to lowercase (this is useful when distinguishing between words like ‘this’ and ‘This’.
if statements can be useful for selecting certain words or phrases from text

EXAMPLES


word sense disambiguation – the sense of a word in a given context
- use contexts clues to discern the meaning of an ambiguous word
- useful in knowing how to respond to the user correctly
![]()
pronoun resolution – detects the subjects and objects of verbs
- find the antecedent

EXAMPLE

In this example, it is important to know what object is being talked about because in some languages, gender matters. If it were to be the thieves that were found, the translation would be masculine. If it were to be the paintings however, the translation would be feminine.
Ch. 2 Accessing Text Corpora and Lexical Resources
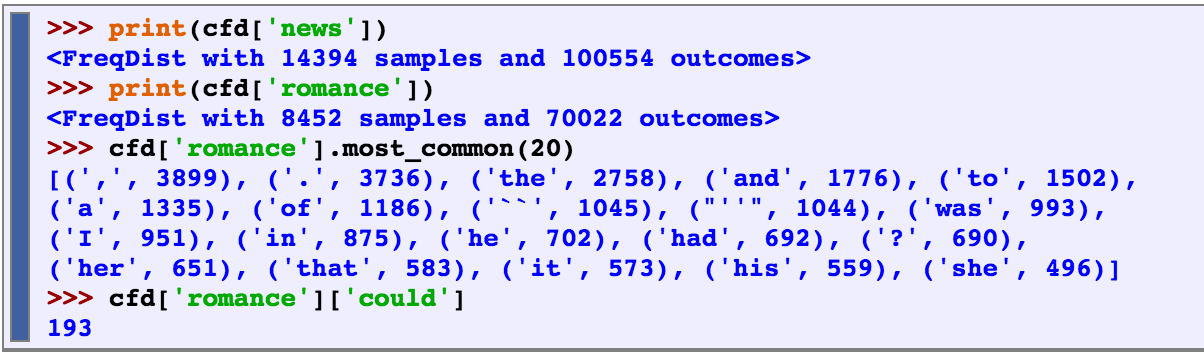
Conditional Frequency Distribution
Conditional frequency distribution is good for comparing the frequency distribution between two different genres.
EXAMPLES

![]()
Lexical Resources
A lexical entry consists of a headword (also known as a lemma) along with additional information such as the part of speech and the sense definition.
Two distinct words having the same spelling are called homonyms.
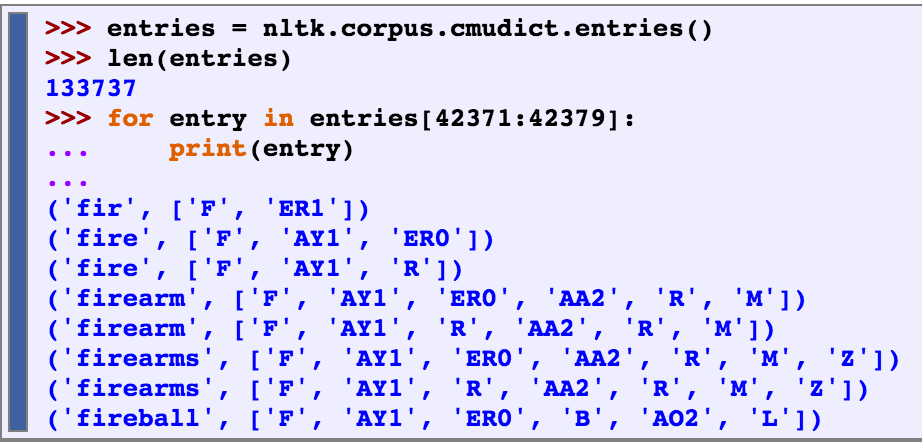
A Pronouncing Dictionary
NLTK includes the CMU Pronouncing Dictionary for US English, which was designed for use by speech synthesizers. For each word, this lexicon provides a list of phonetic codes — distinct labels for each contrastive sound — known as phones. Observe that fire has two pronunciations (in US English): the one-syllable F AY1 R, and the two-syllable F AY1 ER0.
Senses and Synonyms
Since everything else in the sentence has remained unchanged, we can conclude that the words motorcar and automobile have the same meaning, ie. they are synonyms.

having synonyms are good for eliminating ambiguity
synset – a “synonym set” or collection of synonyms
lemma – the pairing of a synset with a word
![]()
TERMS
hyponym – a more specific term of a general term ex: a shirt is a hyponym of clothing
hypernym – the opposite of a hyponym; a more general term of a specific term ex: color is a hypernym of red
meronyms – things contained in an item ex: the parts of a tree are its trunk, crown
holonyms – the item contained in things/ a group ex: a collection of trees forms a forest
hypernyms and hyponyms, and meronyms and holonyms are called lexical relations
Ch. 3 Accessing Raw Text
Accessing Text from the Web
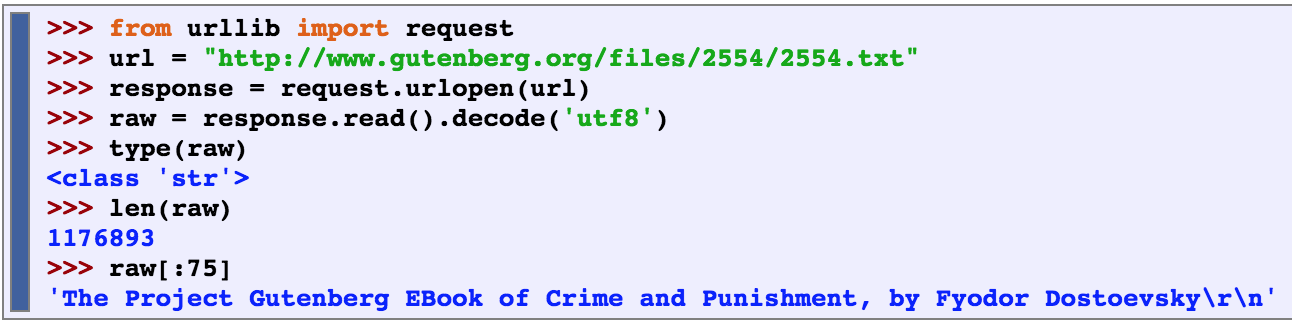
![]()
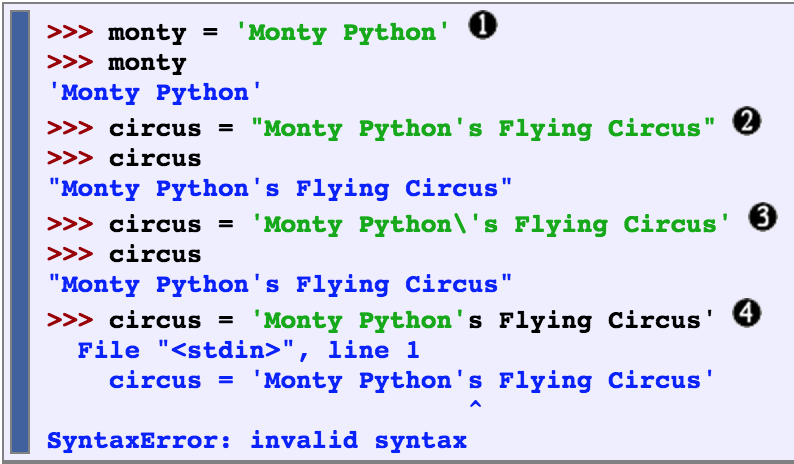
Strings
Strings are specified using single quotes or double quotes. A sequence of two strings can be joined into a single string. We need to use a backslash or parentheses so that the interpreter knows the statement is not complete after the first line
.


Strings and lists are both kinds of sequence. We can pull them apart by indexing and slicing them, and we can join them together by concatenating them. However, we cannot join strings and lists (we cannot technically join then, however we can change strings to lists or lists to strings using the join and split functions). Elements in a list can be altered, whereas strings cannot.

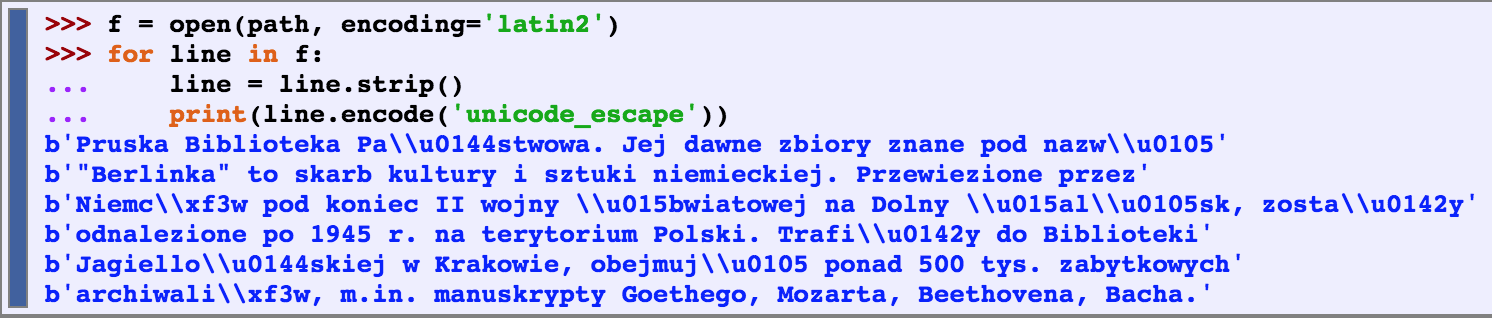
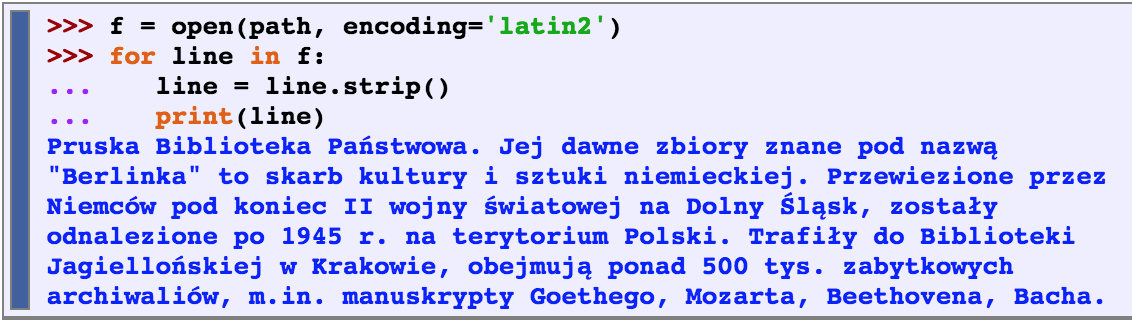
Unicode
Unicode supports over a million characters. Each character is assigned a number, called a code point. In Python, code points are written in the form \uXXXX, where XXXX is the number in 4-digit hexadecimal form.
translation into Unicode is called decoding (reading code into unicode)
translation out of Unicode is called encoding (writing out from unicode)
EXAMPLES
![]()
The caret symbol ^ matches the start of a string, just like the $ matches the end. The ? symbol specifies that the previous character is optional. Thus “^e-?mail$” will match both email and e-mail.
![]()

Segmentation
Tokenization is an instance of a more general problem of segmentation. Sentence segmentation is tokenizing a sentence.
![]()
How to segment sentences and words…

Replacement Field
We can have any number of placeholders, but the str.format method must be called with exactly the same number of arguments.
![]()

Text Wrapping
When the output of our program is text-like, instead of tabular, it will usually be necessary to wrap it so that it can be displayed conveniently. Consider the following output, which overflows its line, and which uses a complicated print statement.
![]()
We can take care of line wrapping with the help of Python’s textwrap module. For maximum clarity we will separate each step onto its own line.

Cited: “Natural Language Processing with Python.” NLTK Book. N.p., n.d. Web. 08 June 2015.
