
Ch. 7 Extracting Information from Text
Information Extraction
structured data – a regular and predictable organization of entities and relationships
ex: looking at a relation between companies and locations, if we were given a location, we would like to discover which companies do business in that location

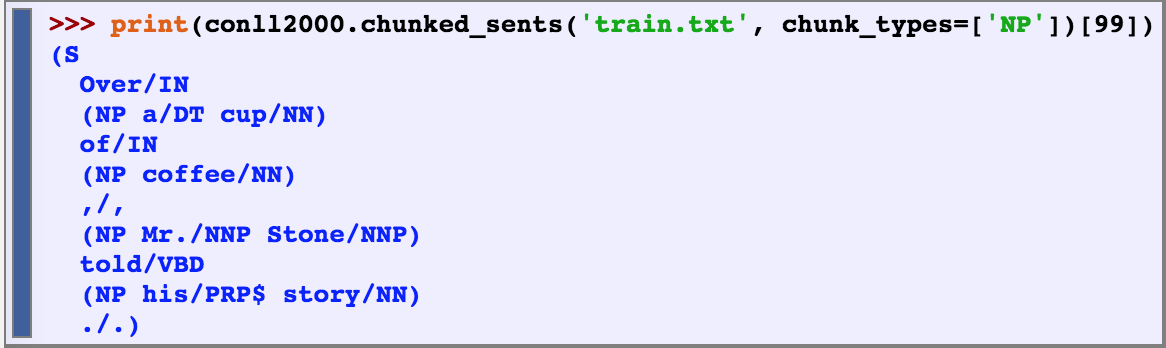
above is example code that demonstrates how the relations work. the form (element1, relation, element2) is key for locating key words as seen in line 6 of the code. query is assigned to the for-loop used to look for companies in Atlanta.
named entity detection – search for mentions of potentially interesting entities in each sentence
relation detection – search for likely relations between different entities in the text

Chunking
chunking – the basic technique used for entity detection. segments and labels multi-token sequences. chunking usually selects a subset of tokens and the pieces produced by a “chunker” do not overlap in source text
chunk – the larger boxes (ex: NP)
ex: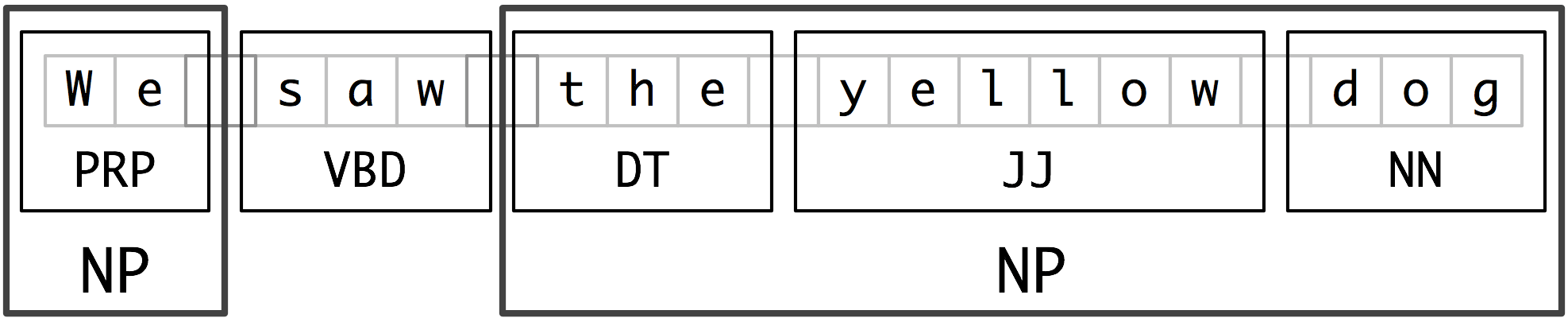
noun phrase chunking – also known as NP-chunking; searching for chunks corresponding to individual noun phrases. it is useful for getting POS tag information
![]()
above is an example of noun phrase chunking where the brackets indicate the noun chunks
chunk grammar – rules that indicate how sentences should be chunked (rules are specific to cases, there is not a general set.)
ex: single regular-expression rule – an NP chunk should be formed whenever the chunker finds an optional determiner (DT) followed by any number of adjectives (JJ) and then a noun (NN).

above is an example of a simple regular expression base on the NP chunker. it classifies every word’s POS.
Tag Patterns
tag patterns – a sequence of POS tags delimited using angle brackets. (ex:?*. they are similar to regular expressions. the example tag pattern will chunk any sequence of tokens starting with an optional determiner, followed by zero or more adjectives, followed by zero or more nouns.
if a tag pattern matches at overlapping locations then the leftmost match takes precedence
![]()
nltk.RegexParser uses a set of regular expression patterns to specify the behavior of the parser
in the above example, we are assigning a list of 3 tuples to the variable noun. the grammar variable shows how we are taking leftmost precedence of the nouns. when printed, all three will show, but the ones in the statement NP money/NN market/NN) are the two that are consecutive since they are the first two out of three.
Chinking
chink – a sequence of tokens that is not included in a chunk.

in the above example, the output will not have brackets around anything that we are chinking.
![]()
the first statement shows you how to chunk everything and the second statement shows you have to chink specific words/phrases.
*remember chinking: “} – {” vs. chunking: “{ – }”
IOB tags – tag a chunk structure after parsing with either I (inside) if the token is inside a chunk, O (outside) if the token is outside a chunk, or B (begin) if the token marks the beginning of a chunk.
the chunk_types argument selects a specific type of argument in a text
ex:
in the above example, all the nouns were not chinked while everything else was. (the nouns are still in parentheses)
Evaluation Chunkers
we can evaluate chunkers and how precise they are by using the cp.evaluateargument.

Recursion in Linguistic Structure
most of the chunk structures we have worked with have been relatively flat, however, it is possible to build chunk structures with more depth by creating chunk grammar containing recursive rules.

above is an example of a chunk structure with more depth. the more rules, the more depth. keep in mind that there is a shortcoming in this code — the word “saw” is missing the solution to this and other patterns like this is to get the chunker to loop over its own patterns/repeat the process.
Trees
tree – a set of connected labeled nodes, each reachable by a unique path from a distinguished root node.
its best to use a recursive function to traverse through a tree

Named Entity Recognition
Named Entities – definite noun phrases that refer to a specific type of individual
ex: 
Named Entity Recognition – a system whose goal is to recognize any mention of any named entity. it is useful for identifying relations in Information Extraction, and Question Answering by improving the precision of Information Retrieval.
gazetteer – a geographical dictionary that is useful for identifying named entities although is very error prone since it sometimes finds incorrect locations on words that aren’t meant to be located and some terms are ambiguous .
ex: 
incorrect locations: Sanchez in the Dominican Republic, On in Vietnam, Of in Turkey, etc.
nltk.ne_chunk() is a classifier that NTLK has already provided to be able to recognize named entities. (if we set the parameter binary=True then the named entities will be tagged as NE, or else the classfier will label such as PERSON, ORGANIZATION, and GPE.

look at the difference in the above example when you have binary=True in the parameters versus when you don’t; some things are classified differently.
Relation Extraction
after we identify named entities between text, we want to extract the relations that exist between them. normally this is in the form (X, a, Y) where ‘X’ and ‘Y’ are named entities like an ORGANIZATION, or LOCATION, and ‘a’ is the relation term that we are looking for.
Ch. 8 Analyzing Sentence Structure
generative grammar is a language that is made up of a collection of grammatical sentences.
ex: a. I went shopping at the mall.
b. I got a new shirt.
c. My mom said I went shopping at the mall and I got a new shirt.
sentence c is made up of both sentence a and b; an example of how generative grammar works.
this chapter talks about grammar and parsing, patterns of form in a sequence of words and how to appropriately respond to phrases without being mislead by the sequence of words (an ambiguous sentence).
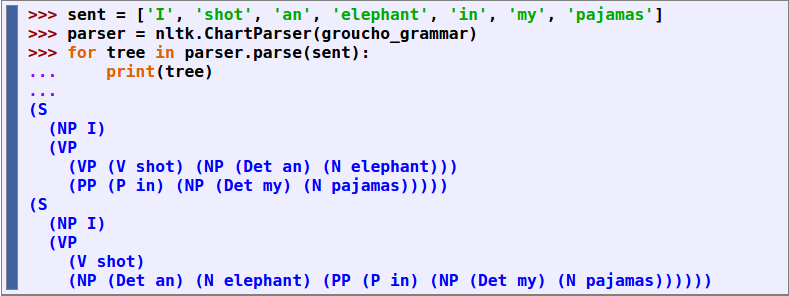
in the above picture code is shown to represent the two trees that show how the sentence “I shot an elephant in my pajamas” are analyzed. one way with the elephant in the pajamas and the other with the person in their pajamas shooting the elephant.
coordinate structure – two phrases are joined by a coordinating conjunction such as and, but or or
** If A and B are both phrases of grammatical category X, then A and B is also a phrase of category X. Meaning that we can combine two of the same types of phrases (noun phrases, adjective phrases, etc.) and have the sentence still make sense. However we cannot combine two different types of phrases in a sentence.
constituent structure – the observation that words combine with other words to form units aka taking a well-formed long sentence and replacing it with a shorter one without altering the meaning of the sentence

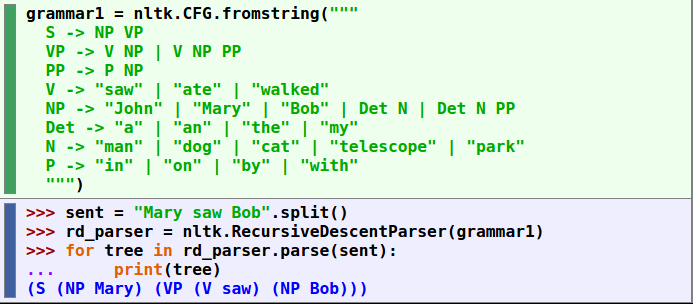
above in the green box we define the word bank(also known as a grammar production) we can use in our sentences and in the blue box we create our sentence and use a for loop to go through each word and assign what grammar type goes with each word as defined in the green box.
Recursion in Syntactic Structure
recursive grammar – when a category on the left hand side of a production is also on the right hand side of a production
ex:

there are nested sentences within this tree with “chatterer said”, then “Buster thought”, and lastly “the tree was tall”. they have the same sentence structure within one another.
Parsing with Context Free Grammar
parser – processes input sentences according to the productions of a grammar. there are two type of parsing algorithms — recursive descent parsing and shift-reduce parsing.
Recursive Descent Parsing – breaking a high-level goal into several lower-level subgoals. It builds a parse tree with the initial goal to be the root node. (ie. if your goal is to find S, the S -> NP VP production replaces the goal with two subgoals — one to find NP and one to find VP. in this case, S would be the root node and NP and VP would be the children).
ex:
NLTK provides a recursive descent parser by using nltk.RecursiveDescentParser
here is an example of how it can be used:
![]()
Shift-Reduce Parser – tries to find a sequence of words and phrases that correspond to the RIGHT HAND side of a grammar production, and replace them will the left hand side until the sentence is reduced to an S.

NLTK also provides a shift reducing parser by using nltk.ShiftReduceParser.
here is an example of how it is used:
![]()
left-corner parser- a hybrid between the bottom-up and top-down parsing approaches we have seen. it is a top-down parser recursive productions (unlike a recursive descending parser).
A well-formed substring table is a table that neatly displays the grammar type of each word in a table.
ex:

in this example we create out sentence and split it, and then display the tokens in a nice neat table, displayed in the same order the sentence is in. so “I” is a noun phrase (NP), “shot” is a verb (V), “an” is a determiner (Det), and so on.
Dependencies and Dependency Grammar
dependency grammar focuses on how words relate to other words. it is a binary asymmetric relation between a head and its dependents
here is an example of a dependency graph:
a dependency graph is said to be projective if all the words are written in linear order and the arrows can be drawn above the words without crossing — a word and its descendants form a contiguous sequence of words within the sentence.
Ch. 9 Building Feature Based Grammars
in this chapter, we are going to learn how to declare the features of words and phrases. here is an example:
![]()
the features are to the left of the colons and the values are to the right. (CAT is the grammatical category, ORTH is the spelling, REF is the referent, and REL is the relation).
feature structures – the pairing of features and values. they contain various kinds of information about grammatical entities for example, what “semantic role” is played by a POS. (is it a subject or object?)

in the example a. the dog runs and b. the dog run, we can see the verb co-vary with the syntactic properties of the subject noun phrase (also called an agreement)
below is an example of how syntactic agreement works — grammatical word sequences. there is a singular and a plural version

vs

in ex (5), there is only one subject, noun phrase, verb phrase, etc. (singular) however in ex (6), using the same template, there is both a singular version and a plural version as well. every production in (5) has two counterparts in (6) this is helpful with a large set of grammar that covers a good section of the english language. (this production can be inefficient in that it comes at a cost of “blowing up” the number of productions very quickly)
Using Attributes and Constraints
linguistic categories have properties (ex: a noun has a property of being plural). an example of this notation for this is n[NUM=pl]
this is helpful in that we can allow variables to replace feature values (like templates). here is an example:

here we allow the “?” to be a variable that can be either singular (sg) or plural (pl); that way we only have to write one production and not two!


think of these productions like trees — 10(a) and 11(a) can be combined in a production like 10(b) and 11(b) as well because the values of Det and N must be the same. however 10(a) and 11(b) cannot be combined.
