
Ch.4 Writing Structured Programs
Assignment – always copies the value of an expression, but a value is not always what you might expect it to be

in the above example, the string “Monty” is set to variable foo. foo is then set to the new variable bar. the string “Python” is then reassigned to foo. “Monty” is the string being printed out when calling bar however because when foo was set to bar, foo held the string “Monty”, not “Python”.

in the above example, the list “Monty Python” is set equal to variable foo. foo is then set to the new variable bar. the string “Bodkin” is set to the second space in the list foo. “Monty Bodkin” is printed out when calling variable bar because the “value” of a structured object such as a list is actually just a reference to the object, not a copy.


Observe that changing one of the items inside our nested list of lists changed them all. This is because each of the three elements is actually just a reference to one and the same list in memory.
Equality
The is operator tests for object identity. We can use it to verify our earlier observations about objects. First we create a list containing several copies of the same object, and demonstrate that they are not only identical according to ==, but also that they are one and the same object.

in this example, the data in the list are the same but the addresses are different. Therefore, the statement with the equality sign is true and the statement with the is operator is false.
Conditionals
In the condition part of an if statement, a nonempty string or list is evaluated as true, while an empty string or list evaluates as false.
If the if clause of a statement is satisfied, Python never tries to evaluate the elif clause that comes after.
The all and any functions can be used to see if all or any items meet some specific condition
![]()
Sequences
Another sequence besides a string or list is a tuple– they are formed with the “,” operator and are usually in parentheses. They can be indexed and/or sliced, and have a length.

the above example shows the tuple being declared, printed, indexed, sliced, and prints the length (in that order)

this example compares a string (raw), list (text), and a tuple (pair) to show the differences in the structures when being indexed, sliced, and taken the length of.
Tuples can also be used to rearrange the sequence of words. ![]()
the second line in this example assigns/replaces a new arrangement of the words with the old arrangement.

the zip and enumerate functions are examples of how tuples are used. zip takes in two parameters and prints out the word, and type of word it is (ie. noun, adjective, etc.) the enumerate function takes in one parameter and prints out the index and the word.
A good way to decide when to use tuples vs lists is to ask whether the interpretation of an item depends on its position. Another way to spot the difference is that in Python, lists can be changed and tuples cannot.
Ch. 5 Categorizing and Tagging Words
Parts Of Speech
A POS-tagger, processes a sequence of words and attaches a POS tag to each word. With the help of a POS-tagger, the computer has a better chance of pronouncing words correctly. A tagset is a collection of tags for a particular set.
lexical categories – parts of speech
Using a Tagger
![]()
in the above example, the word refuse is used in two different ways — refUSE, a verb meaning “deny,” and REFuse, a noun meaning “trash” (i.e. they are not homophones). Thus, we need to know which word is being used in order to pronounce the text correctly.
![]()

above are some keywords used in tagging. an example of them being used is in the picture above the table.
How does the program provide this extra data?
By using superficial analysis of the distribution of words in a text. One way to provide the tags is to use the similar function on a word, and by looking at the POS for the words similar, find the correct POS tag.

In the above example, the words “woman”, “bought”, “over”, and “the” are used in the similar function and each output words used in a similar context as itself. When searching for “woman”, the system finds mostly nouns used in a similar context. For “bought”, verbs; “over”, prepositions; and for “the”, the system finds mostly determiners. By recognizing that most of the similar words are one specific tag, the program can conclude that the word being searched is probably also in that POS tag category.
Tagged Corpora
tagged tokens are tuples with the form “word/tag”. they can be represented by using the str2tuple function.

in the example above, remember that split is used to split a string into a list via spaces. str2tuple is used to convert sent into pairs. by using a for loop, the output is a list of pairs or tuples with the pairs being in tagged token form (word/tag).
below is a table of tags, meanings and examples:

Nouns
Nouns generally refer to people, places, things, or concepts, e.g.: woman, Scotland, book, intelligence. Nouns can appear after determiners and adjectives, and can be the subject or object of the verb.
Verbs
verbs typically express a relation involving the referents of one or more noun phrases.
Dictionaries in Python


in the above example, this is how you would define words in a dictionary. the keyword being in the brackets and the POS on the right hand side of the assignment operator.
*there is a way of storing multiple values in that entry: we use a list value, e.g. pos['sleep'] = ['N', 'V']
Inverting a Dictionary
Inverting a dictionary is when you search a key and get the dictionary term from it. If d is a dictionary and k is a key, we type d[k] and immediately obtain the value. Finding a key given a value is a much slower process.
*make sure no two keys have the same values
If multiple keys have the same value, then we have to use append() to accumulate the words for each part-of-speech.

A summary of commonly-used methods and idioms involving dictionaries.
Automatic Tagging
Default Tagger – find POS that is most used within the text and tag all the tokens as that POS. It is right about 1/8 of the time.

Regular Expression Tagger – assigns tokens on a basis of matching patterns. It is right about 1/5 of the time.
The Lookup Tagger – the lookup tagger is right about 1/2 of time time. it knows the tags for the 100 most used words. if a word is not one of the 100 most used, the lookup tagger will only store word-tag pairs for words other than nouns, and whenever it cannot assign a tag to a word it will invoke the default tagger.
Unigram Tagger – for each token, assign the tag that is most likely for that particular token. A unigram tagger is like a lookup tagger except that it can be trained. We train a Unigram tagger by specifying tagged sentence data as a parameter when we initialize the tagger. The training process involves inspecting the tag of each word and storing the most likely tag for any word in a dictionary, stored inside the tagger.

The different types of tagging can be combined using the backoff technique.
Backoff is a method for combining models: when a more specialized model (such as a bigram tagger) cannot assign a tag in a given context, we backoff to a more general model (such as a unigram tagger).
Determining the Category of a Word
In order to decide what category a word goes into, we should use three different types of clues to help narrow down the search — morphological, syntactic, and semantic.
Morphological – The internal structure of a word may give useful clues as to the word’s category.
For example, -ness is a suffix that combines with an adjective to produce a noun, e.g.happy → happiness, ill → illness. So if we encounter a word that ends in -ness, this is very likely to be a noun. Similarly, -ment is a suffix that combines with some verbs to produce a noun, e.g. govern → government and establish → establishment.
Syntactic – the context in which a word occurs.
For example, assume that we have already determined the category of nouns. Then we might say that a syntactic criterion for an adjective in English is that it can occur immediately before a noun, or immediately following the words be or very. According to these tests, near should be categorized as an adjective:
a.) the near window.
b.) the end is (very) near.
Semantic – the meaning of a word. “the name of a person, place or thing”.
Open class – class that can be added to (ie. nouns) there are not a limited set of words for this class.
Closed class – class that is closed. cannot be added to (ie. prepositions) there is a limited set of words that can be in this class.
Ch. 6 Learning to Classify Text
Classification
Classification – labeling input correctly/putting given input in the correct class
ex: deciding if email is spam or not; categorizing topics (sports, religion, politics, etc.)
Creating a Classifier
The first step in creating a classifier is deciding what features of the input are relevant, and how to encode those features.
ex: an important feature for gender identification is to get the last letter of the name. we can import a file of names and use it as test data to get an idea of which gender to classify last letter names in. creating likelihood ratios are helpful for comparing different outcome relationships.

above is an example of a likelihood ratio output.
Choosing Features
choosing the right features can have a big impact on how the program learns/is trained. start with the “kitchen sink” approach where you include all the features you can think of that would be relevant. However, if you provide too many features, the algorithm will reply too much on idiosyncrasies from the training data that wont help with new data later on.
error analysis – a productive method for refining a feature set

above, we are testing a feature set for the last letter in a name for gender verification. there are errors so we must do error analysis. according to the book, most names ending in n are male while names ending in yn are female. and names ending in h are mostly female even though names ending in ch are usually male names.

here we refine the set to make it more accurate and below we are testing and training.
![]()
Part-of-Speech Tagging
we can create a POS tagger ourselves by training a classifier to figure out which suffixes are most informative.
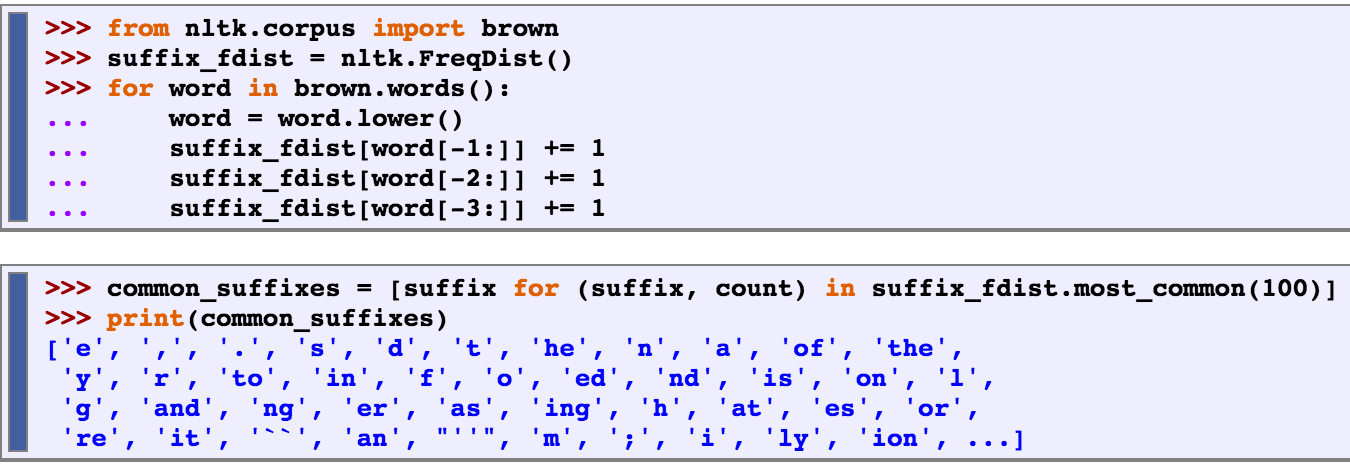
here we are grabbing the suffix of the words in the brown library, and printing out the 100 most common ones used. the suffixes range from the last letter to the last 3.
Sentence Segmentation
whenever we encounter a symbol that could possibly end a sentence, such as a period or a question mark, we have to decide whether it terminates the preceding sentence.
![]()
the above example is creating a feature set for punctuations to help decide if a sentence has ended or not.
Recognizing Textual Entailment (RTE) – the task of determining whether a given piece of text T entails another text called the “hypothesis”

above is an example of a feature set for RTE. It checks extra hypothesis words and overlapping words.
Test Set
a test set is an evaluation set that typically has the same format as the training set except it is not the same set as the training set. it is important that the test is different from the training set because if we just use the test set then the model will just memorize the input instead of learning how to respond to new examples.
Accuracy
accuracy is used to measure/evaluate a classifier. it measures the percentage of inputs in a test set that the classifier labels correctly. the function nltk.classify.accuracy() will calculate the accuracy of a classifier model on a given test set. make sure to consider the frequencies of an individual class in the test set.
![]()
Precision and Recall
Another instance where accuracy scores can be misleading is in “search” tasks, such as information retrieval, where we are attempting to find documents that are relevant to a particular task. Since the number of irrelevant documents far outweighs the number of relevant documents, the accuracy score for a model that labels every document as irrelevant would be very close to 100%.
True positives (TP) – relevant items that are correctly defined as relevant
True negatives (TN) – irrelevant items that are correctly identified as irrelevant
False positives (FP) – also known as Type I errors, irrelevant items that are incorrectly identified as relevant
False negatives (FN) – also known as Type II errors, relevant items that are incorrectly identified as irrelevant
Precision – indicates how many of the items that we identified were relevant
equation: TP/(TP + FP)
Recall – indicates how many of the relevant items that we identified
equation : TP/(TP + FN)
F-Measure – also known as F-Score, combines the precision and recall to give a single score. defined to be the harmonic mean of the precision and recall.
equation: (2 x Precision x Recall)/(Precision + Recall)
Confusion Matrices
confusion matrix – a table where each cell [i,j] indicates how often label j was predicted when the correct label was i. the diagonal entries indicate labels that were correctly predicted and the off-diagonal entries indicate errors.
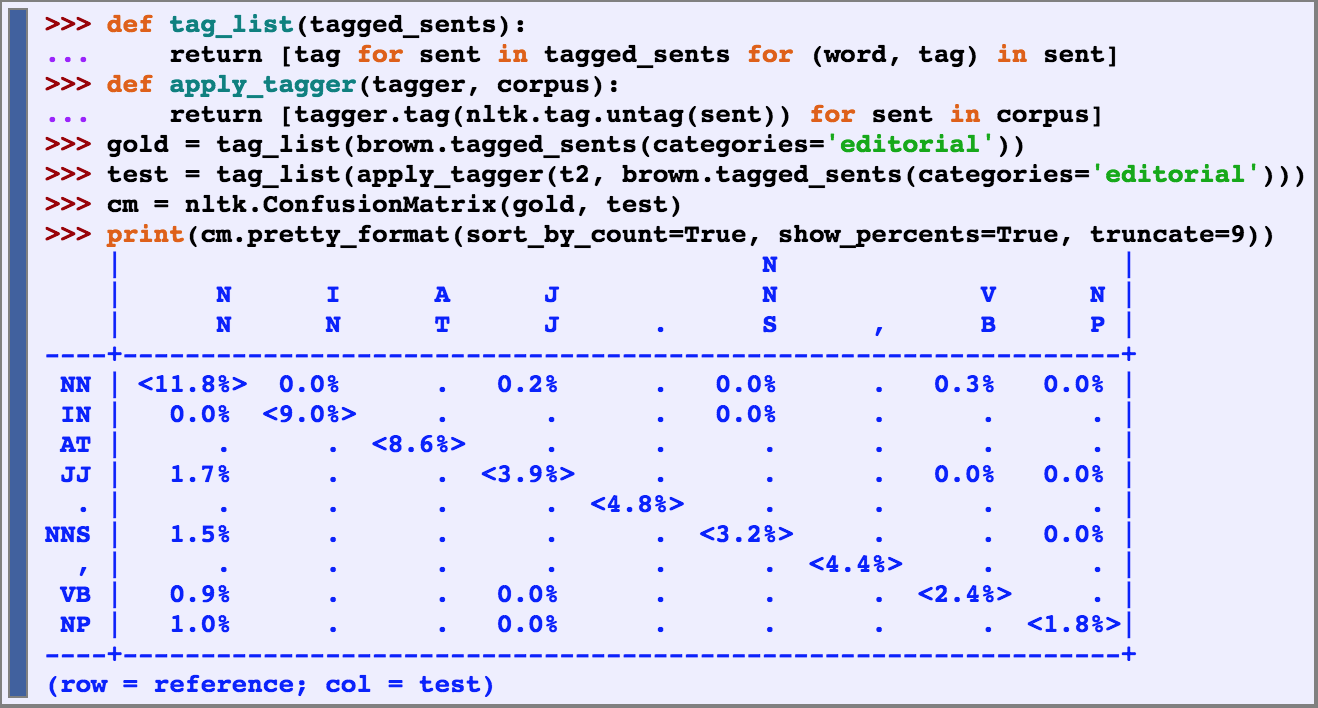
cross-validation – performing multiple evaluations on different test sets then combining the scores from those evaluations. cross validations allow ups to examine how widely the performance varies across different training sets.
folds – subsets of the original corpus. we train a model using all of the data except the data in that fold, and then test that model on the fold
Decision Trees
decision tree – a simple flowchart that selects labels for input value.
decision nodes – check feature values
leaf nodes – assign labels
root node – the initial decision node in a flowchart
below is a decision tree example for the name gender task.

Entropy and Information Gain
information gain – measures how much more organized the input values become when we divide the up using a given feature
entropy – the sum of the probability of each label multiplied by the log probability of that same label
| H = −Σl |in| labelsP(l) × log2P(l). |
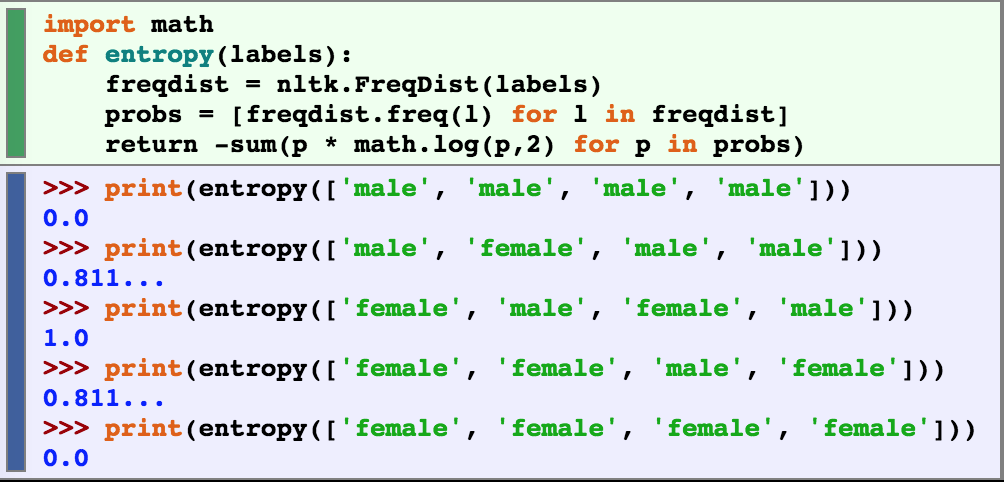
above is code for calculating the entropy of a list of labels
once the entropy of the original set is calculated, we can determine how much more organized the labels become once applying the decision stump.
Calculate the entropy for each of the decision stump’s leaves, and take the average of those leaf entropy values. The information gain is then equal to the original entropy minus this new, reduced entropy. The higher the information gain, the better job the decision stump does of dividing the input values into coherent groups.
Bayes Classifiers
naive Bayes classifiers – every feature gets a say in determining which label should be assigned to a given input value

in the above example, each label (sports, automotive, and murder mystery) get a say in where the input value goes (dark and football). it checks the frequency of each label in the training set and the label whose likelihood estimate is the highest is assigned the input value.
Cited: “Natural Language Processing with Python.” NLTK Book. N.p., n.d. Web. 08 June 2015.
